Video Generation: Using FCNs In An Adversarial Setup
Vincent Casser *, Camilo Fosco *, Justin Lee * and Karan Motwani *: Guided Video Generation Using FCNs in an Adversarial Setup, Technical Report, Harvard University, 2018.
* alphanumerical ordering
Abstract
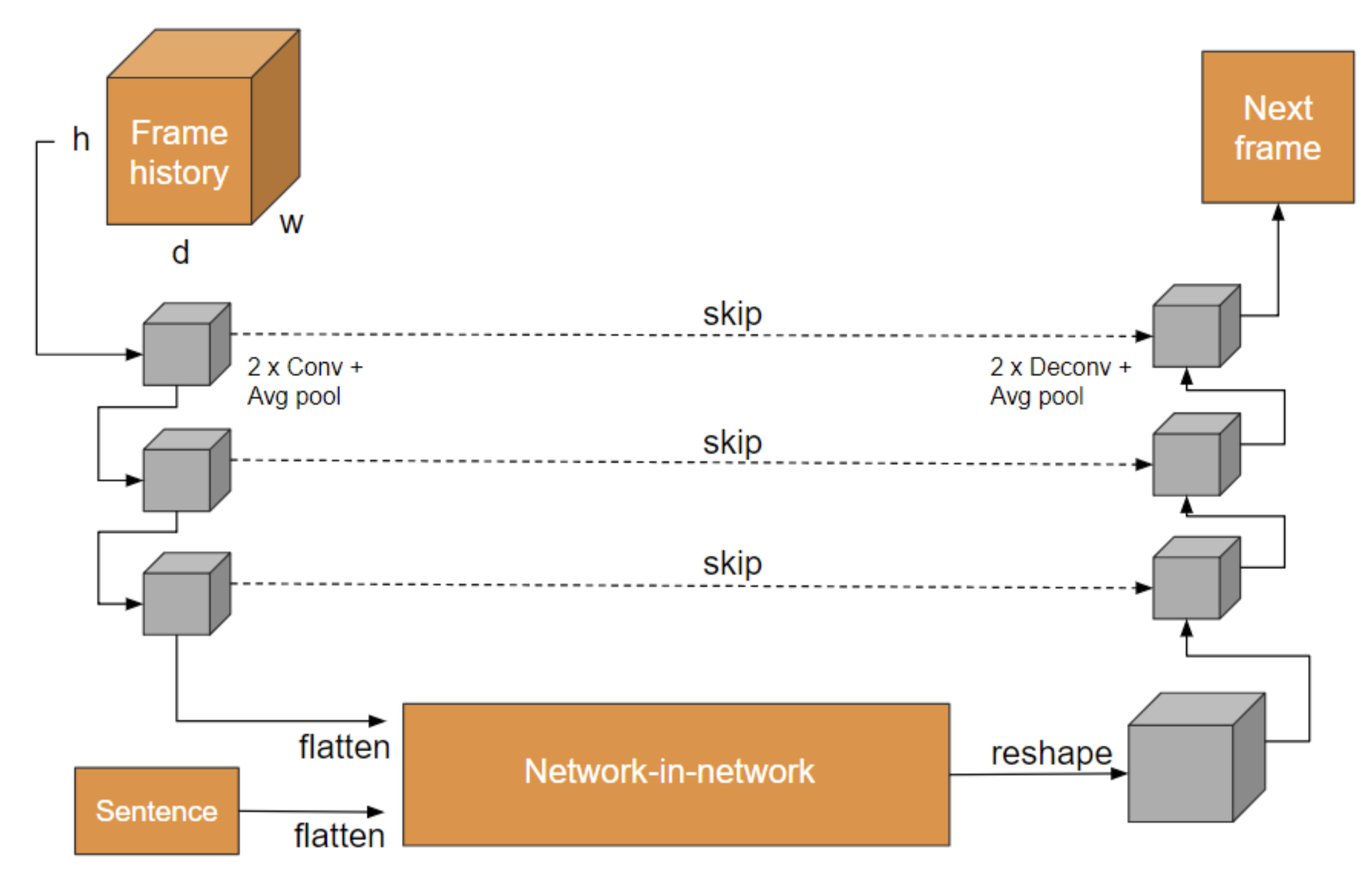
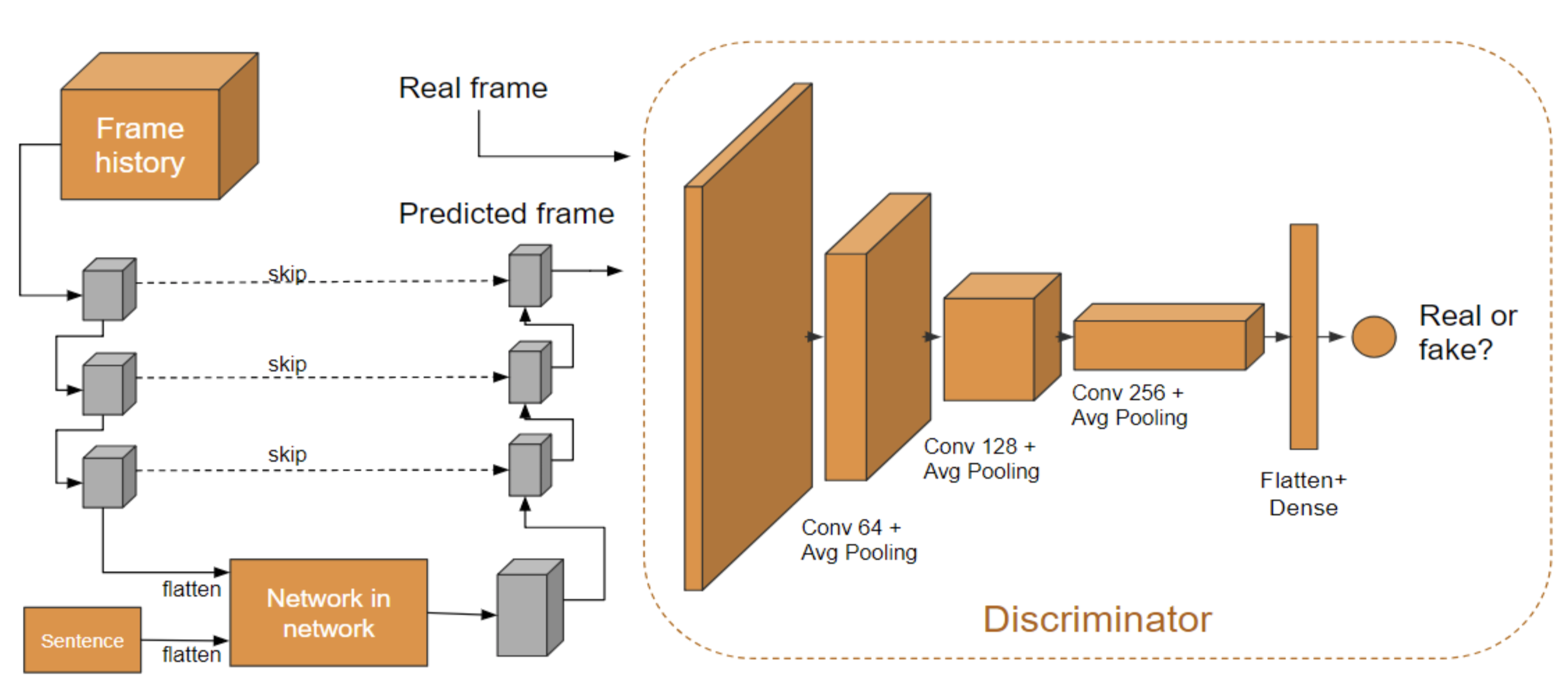
In this project, we present a variety of deep learning based setups for text-to-image and text-to-image sequence generation. Image sequence generation is a challenging task and an actively researched branch within computer vision, posing special challenges such as temporal coherency. To address this problem, we describe a variety of partial and complete solutions that we developed in three stages: (1) Text to Image Synthesis: using a traditional GAN, we generate a single image from a textual representation. (2) Text + Image to Video Synthesis: using a fully convolutional network, we generate an image sequence given a single frame and a description of the action taking place. (3) Inspired by the recent success of generative adversarial networks, we then also train this architecture in a truly adversarial setting. Throughout our work, we make use of different datasets. Primarily, we evaluated our approaches on our own synthetic datasets with increasing difficulty, then moving to natural images from a human action dataset. We also performed text to image synthesis experiments on the T-GIF dataset, but noticed that the high diversity and other issues with this dataset make it rather unsuitable for video generation experiments.
Supplementary Material