Medical NLP: Effective Querying In Medical Case Databases
Vincent Casser *, Shiyu Huang *, Filip Michalsky *, Technical Report, Harvard University, 2018.
* alphanumerical ordering

Abstract
In this project, we introduce a new product to accelerate the adoption of AI in Health Care. In cooperation with the MGH & BWH Center for Clinical Data Science, we applied and optimized natural language processing methods for dealing specifically with medical patient reports collected in hospitals. Reports are written in free form and pose special challenges, such as use of highly specialized vocabulary, abbreviations, typing errors and negated sentences. Standard approaches towards extracting key information or querying, while working well in general use cases, typically fail miserably on these kind of data. We developed a highly efficient search engine for medical databases that helps (i) clinicians to retrieve relevant cases, aiding both clinical diagnostics and treatment, and (ii) machine learning engineers working in the healthcare domain, looking towards automatic extraction of relevant train and test data. Some key features of our engine include
- Automatic negation detection: if key terms are found in a medical report, classify its sentiment to filter out irrelevant reports
- Synonym and misspelling resolution: synonym and misspelling resolution, particularly in medical jargon, is a highly challenging task that MedSearch tackles using learned word embeddings, and therefore is able to relate abbreviations like “ICH” to hemorrhage
- Decentralized structure and security: due to its decentralized structure, heavy computation is performed on a backend server, which allows to store sensitive data securely in a data center and keep control over data access privileges
- Advanced query functionalities: complex querying can be performed, e.g. showing cases of patients with brain hemorrhage without [history of] hypertension
- High efficiency: despite add-ons for advanced multi-processing, all queries can be evaluated in real-time and with low memory overhead
- Scalability: new reports can be added to the database on-the-fly, and the backend scaled across multicore/multi-CPU machines
- User-friendly GUI: our front-end is minimalistically designed and allows for easy interaction, even for untrained individuals.
Supplementary Material

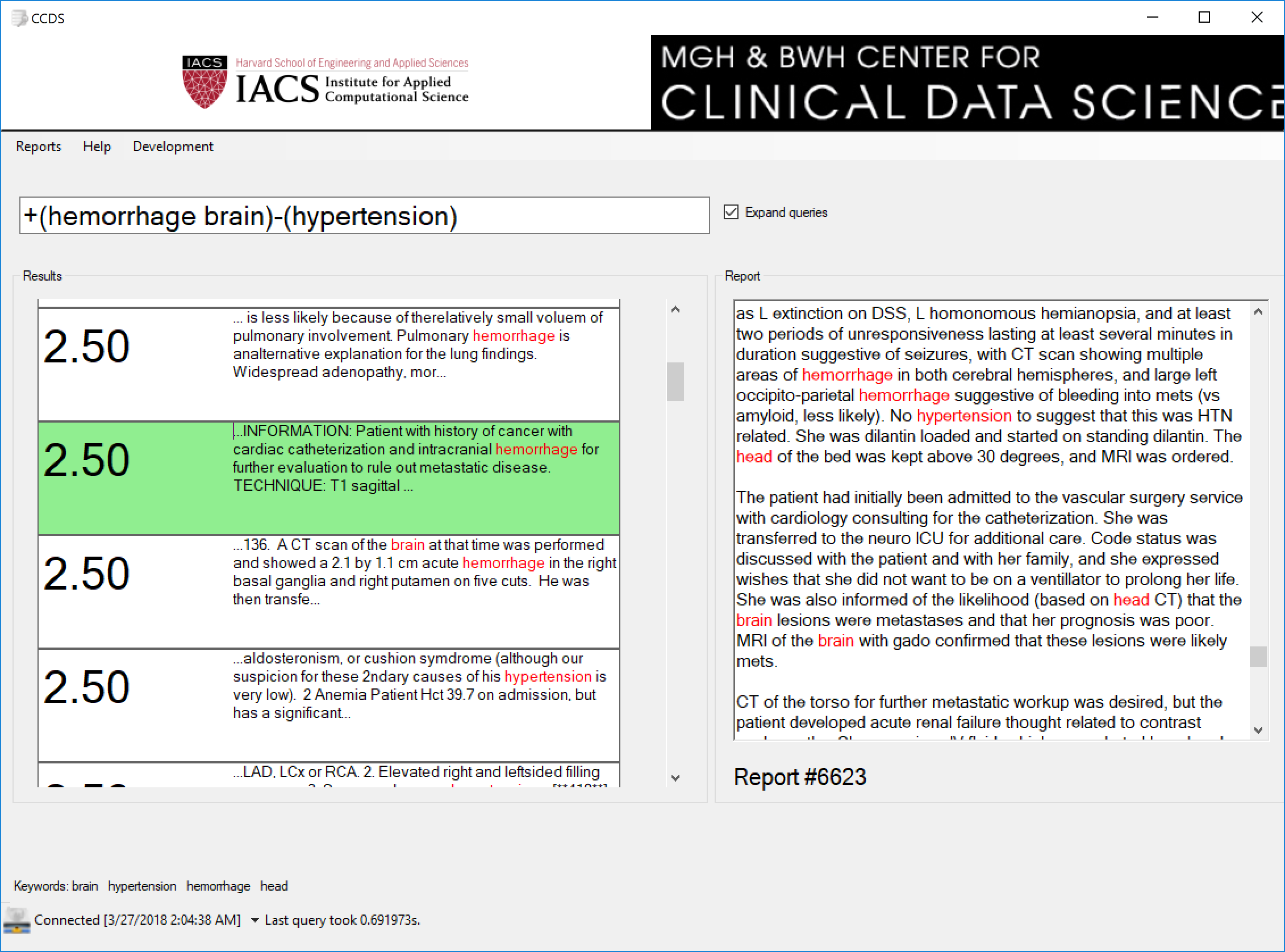
Our processing technology can also be used in other applications, such as traditional analysis and visualization.