Vincent Casser, Soeren Pirk, Reza Mahjourian and Anelia Angelova: “Depth Prediction without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos.” Thirty-Third AAAI Conference on Artificial Intelligence (AAAI’19). (full text)
Related publications
Vincent Casser, Soeren Pirk, Reza Mahjourian and Anelia Angelova: “Unsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics.” International Workshop on Visual Odometry and Computer Vision Applications Based on Location Clues, CVPR’19. (full text)
Abstract
Learning to predict scene depth from RGB inputs is a challenging task both for indoor and outdoor robot navigation. In this work we address unsupervised learning of scene depth and robot ego-motion where supervision is provided by monocular videos, as cameras are the cheapest, least restrictive and most ubiquitous sensor for robotics.
Previous work in unsupervised image-to-depth learning has established strong baselines in the domain. We propose a novel approach which produces higher quality results, is able to model moving objects and is shown to transfer across data domains, e.g. from outdoors to indoor scenes. The main idea is to introduce geometric structure in the learning process, by modeling the scene and the individual objects; camera ego-motion and object motions are learned from monocular videos as input. Furthermore an online refinement method is introduced to adapt learning on the fly to unknown domains.
The proposed approach outperforms all state-of-the-art approaches, including those that handle motion e.g. through learned flow. Our results are comparable in quality to the ones which used stereo as supervision and significantly improve depth prediction on scenes and datasets which contain a lot of object motion. The approach is of practical relevance, as it allows transfer across environments, by transferring models trained on data collected for robot navigation in urban scenes to indoor navigation settings. The code associated with this paper can be found here.
Supplementary Material
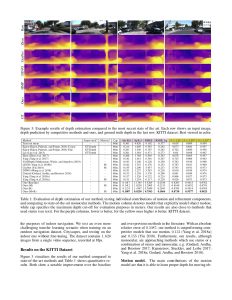
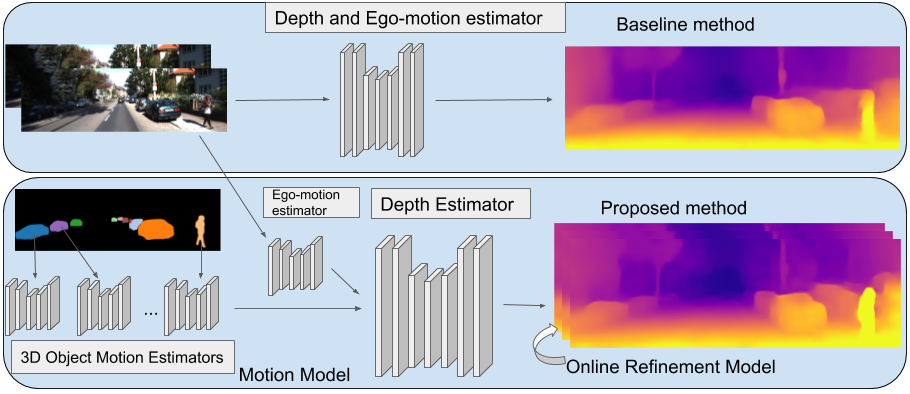
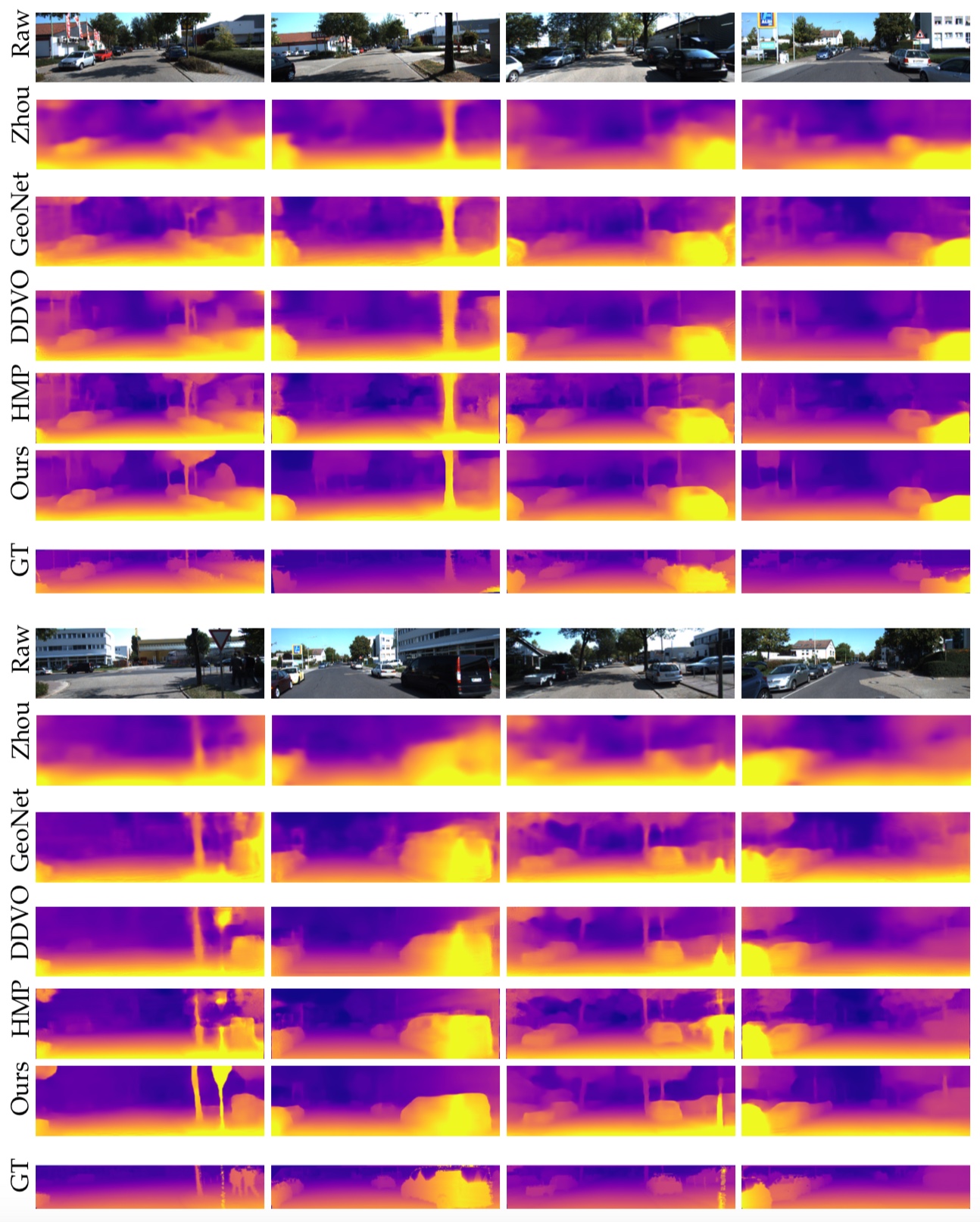
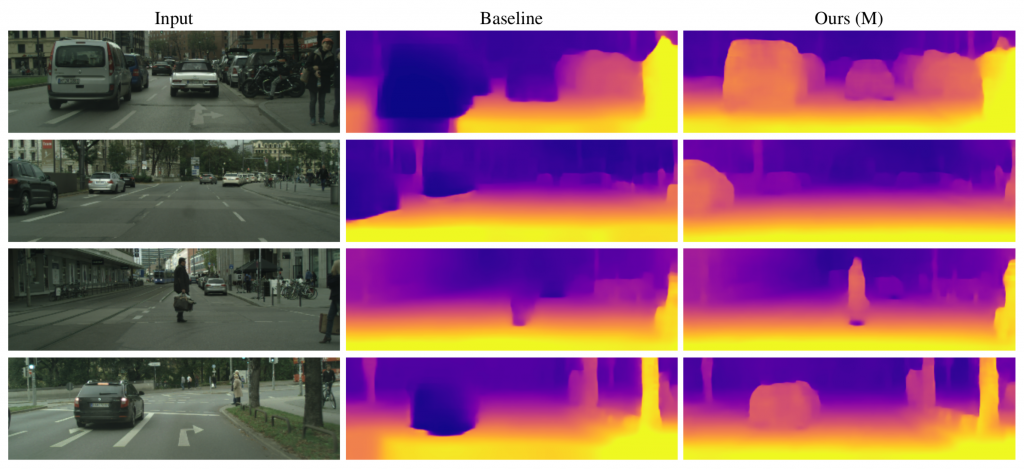
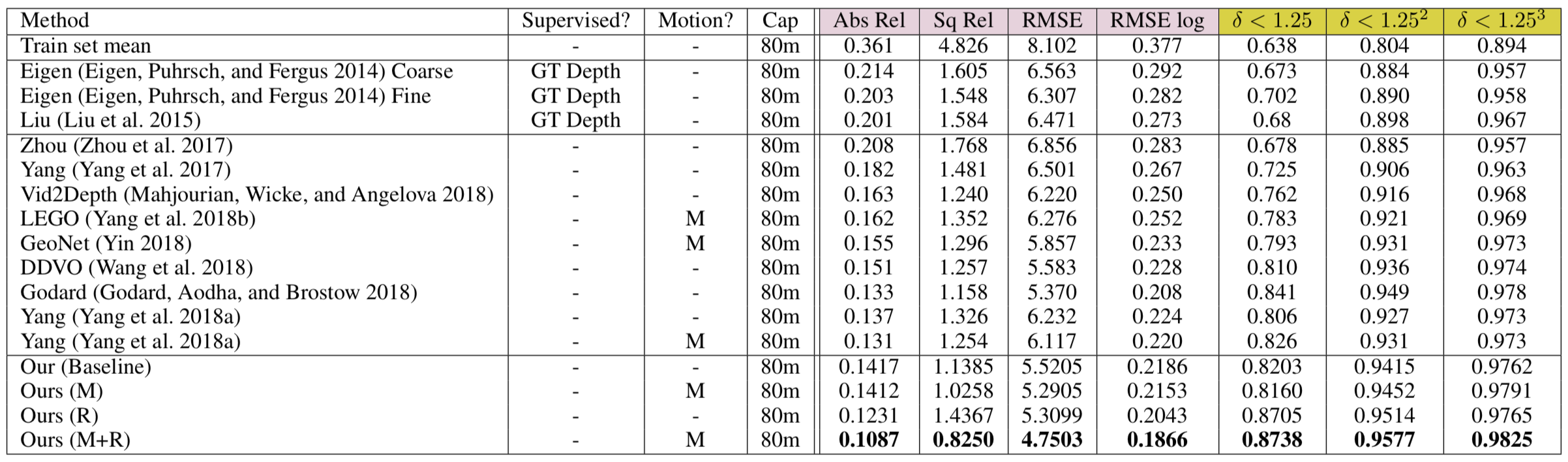
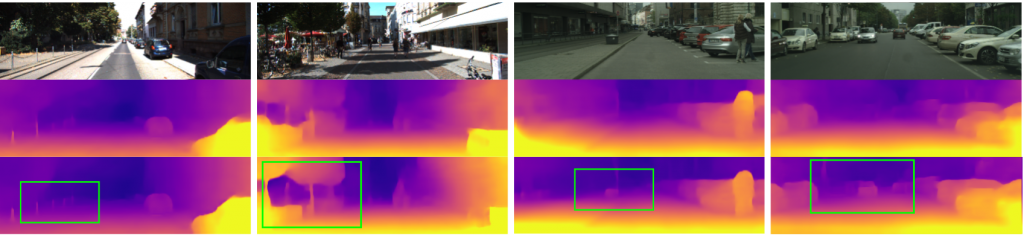
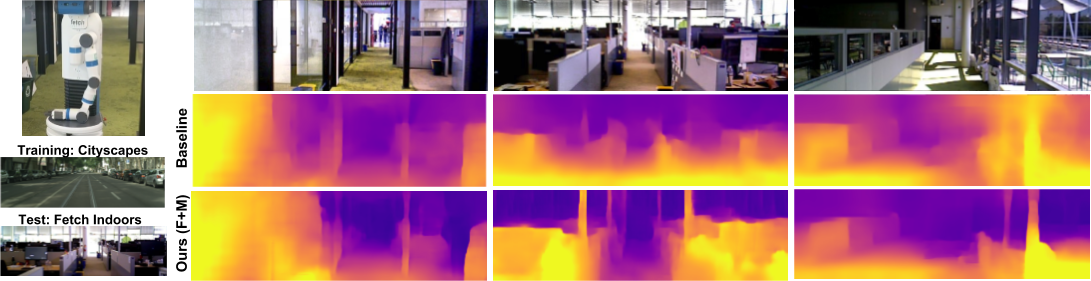
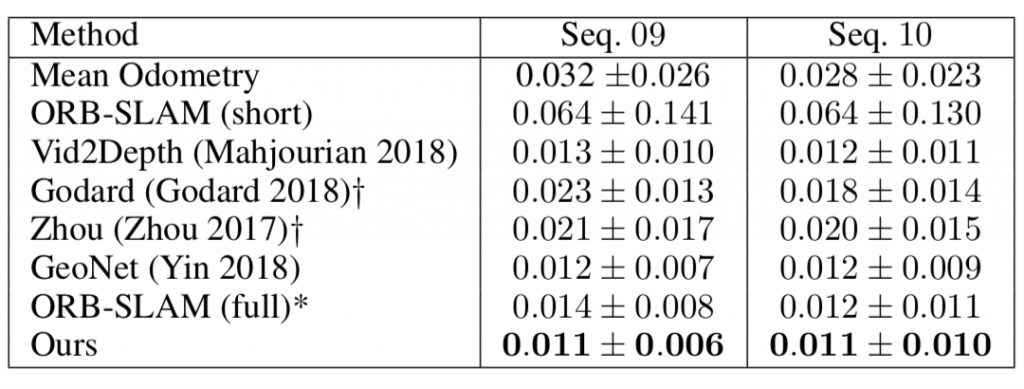
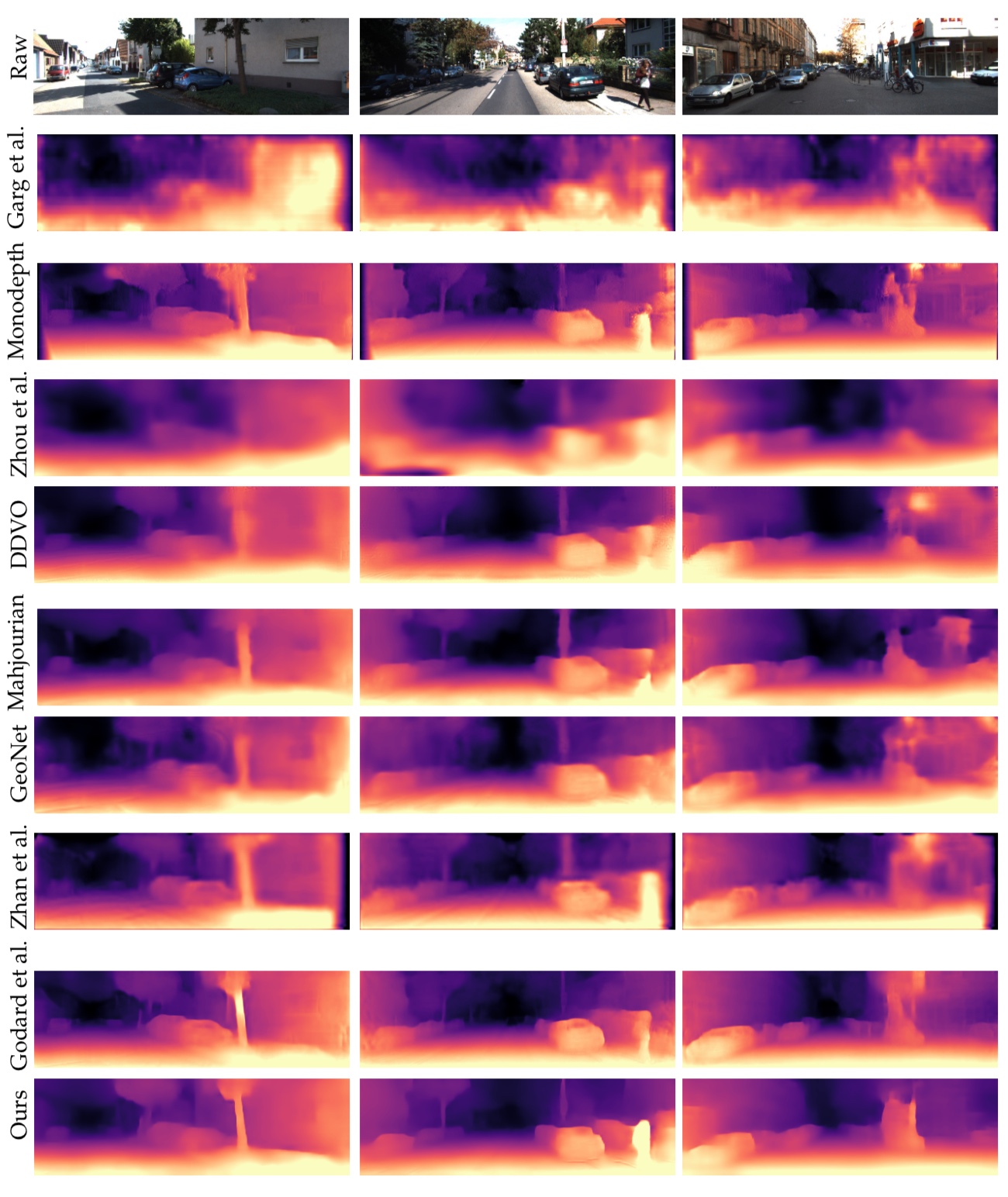
Poster summary for AAAI-19.Problem setup: Obtaining scene depth prediction from RGB image input. Training is unsupervised and from monocular videos only. No depth sensor supervision is used.Our method introduces 3D geometry structure during learning by modeling individual objects’ motions, ego-motion and scene depth in a principled way. Furthermore, a refinement approach adapts the model on the fly in an online fashion.Example results of depth estimation compared to the most recent state of the art. Each row shows an input image, depth prediction by competitive methods and ours, and ground truth depth in the last row. KITTI dataset.Effect of our motion model (M). Examples of depth estimation on the challenging Cityscapes dataset, where object motion is highly prevalent. A common failure case for dynamic scenes in monocular methods are objects moving with the camera itself. These objects are projected into infinite depth to lower the photometric error. Our method properly handles this.Evaluation of depth estimation of our method, testing individual contributions of motion and refinement components, and comparing to state-of-the-art monocular methods. The motion column denotes models that explicitly model object motion, while cap specifies the maximum depth cut-off for evaluation purposes in meters. Our results are also close to methods that used stereo (see text). For the purple columns, lower is better, for the yellow ones higher is better. KITTI dataset.Depth prediction results when training on Cityscapes and evaluating on KITTI. Methods marked with an asterik (*) might use a different cropping as the exact parameters were not available.Depth prediction from a single image compared to Lidar ground truth. KITTI dataset. Depth prediction (top); Lidar ground truth (bottom).Effect of our refinement model (R). KITTI dataset (left columns), Cityscapes (right columns). Training is done on KITTI for this experiment. Notable improvements are achieved by the refinement model (bottom row), compared to the baseline (middle row), especially for fine structures (leftmost column). The effect is more pronounced on Cityscapes, since the algorithm is applied in zero-shot domain transfer, i.e. without training on Cityscapes itself.One benefit of our approach is that individual object motion estimates in 3D are produced at inference and the direction and speed of every object in the scene can be obtained. Predicted motion vectors normalized to unit vectors are shown (yaw, pitch, raw are not shown for clarity).Testing on the Fetch robot Indoor Navigation dataset. The model is trained on the Cityscapes dataset which is outdoors and only tested on the indoors navigation data. As seen our method (bottom row) is able to adapt online and produces much better and visually compelling results than the baseline (middle row) in this challenging transfer setting.Quantitative evaluation of odometry on the KITTI Odometry test sequences. Methods using more information than a set of rolling 3-frames are marked (*). Models that are trained on a different part of the dataset are marked (†).Example results of depth estimation compared to state-of-the-art.